توضیحات
ABSTRACT
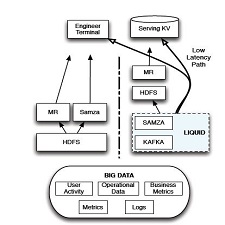
With more sophisticated data-parallel processing systems, the new bottleneck in data-intensive companies shifts from the back-end data systems to the data integration stack, which is responsible for the pre-processing of data for back-end applications. The use of back-end data systems with different access latencies and data integration requirements poses new challenges that current data integration stacks based on distributed file systems—proposed a decade ago for batch-oriented processing—cannot address. In this paper, we describe Liquid, a data integration stack that provides low latency data access to support near real-time in addition to batch applications. It supports incremental processing, and is cost-efficient and highly available. Liquid has two layers: a processing layer based on a stateful stream processing model, and a messaging layer with a highly-available publish/subscribe system. We report our experience of a Liquid deployment with backend data systems at LinkedIn, a data-intensive company with over 300 million users
INTRODUCTION
Web companies such as Google, Facebook and LinkedIn generate value for their users by analyzing ever-increasing amounts of data. Higher user-perceived value means better user engagement, which, in turn, generates even more data. While this high volume of append-only data is invaluable for organizations, it becomes expensive to integrate using proprietary, often hard-to-scale data warehouses. Instead, organizations create their own data integration stacks for storing data and serving it to back-end data processing systems
Year : 2015
Publisher : CIDR
By : Raul Castro Fernandez*,Peter Pietzuch,Kreps, Neha Narkhede, Jun Rao
File Information : English Language / 8 Page / Size : 195 K
Download : click
سال : 2015
ناشر : CIDR
کاری از : Raul Castro Fernandez*,Peter Pietzuch,Kreps, Neha Narkhede, Jun Rao
اطلاعات فایل : زبان انگلیسی / 8 صفحه / حجم : 195 K
لینک دانلود : روی همین لینک کلیک کنید






نقد و بررسیها
هنوز بررسیای ثبت نشده است.