توضیحات
ABSTRACT
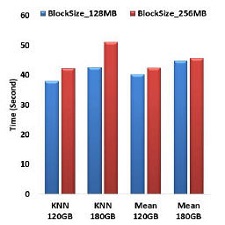
Recent research has demonstrated that social media could provide valuable spatio-temporal data about users activities. However, information extraction and computation from big amount of data pose various challenges. To effectively process massive datasets, several platforms have been developed. Our previous study [20] explored Hadoop-based cloud computing for processing big amount of social media data [9] to study geographic distributions of social media users. In this paper, we investigate an emerging system named Spark and present a timely pilot experience on geospatial big data research. In our study, Spark has been utilized to perform some classic geospatial analyses like K-Nearest Neighbors (KNN), geographic mean and median points, and the distribution of the median points. Our design is tested on an Amazon EC2 cluster. An exemplary study using 60GB, 120GB and 180GB Twitter data has demonstrated the performance achievements by migrating computing tasks from Hadoop to Spark. In our experiments, the Spark-based solution can be up to 2.3x faster than the Hadoop-based solution due to its in-memory processing and coarse-grained resource allocation strategy. In the paper, we also discuss optimization strategies on using Spark for different geospatial computing tasks
INTRODUCTION
Social media data increasingly attract research interests because they become proxy of peoples activities. By extracting locational and temporal information from social media data, trajectories of social media users daily lives can be plotted. Twitter is one of the most popular social media, which has more than 500 million users (302 million active users) around the world, who are generating hundreds of gigabyte (GB) text data per day [3, 9]. Hence, extracting and analyzing information from such big amount of data pose various challenges. In our previous study [20], we designed a Hadoop and Hbase based system, named Dart, to manage the massive data and process geospatial big data computing, which shows Hadoop-based solution has a significant performance improvement [7]. However the design of the Hadoop-based solution leaves ample room for further performance improvement, such as simplifying the two stages of Map and Reduce and replacing hard drivebased computation with in-memory processing
Year : 2016
Publisher : IEEE
By : Zhibo Sun, Hong Zhang, Zixia Liu, Chen Xu, and Liqiang Wang
File Information : English Language / 8 Page / Size : 259 K
Download : click
سال : 2016
ناشر : IEEE
کاری از : Zhibo Sun, Hong Zhang, Zixia Liu, Chen Xu, and Liqiang Wang
اطلاعات فایل : زبان انگلیسی / 8 صفحه / حجم : 259 K
لینک دانلود : روی همین لینک کلیک کنید





نقد و بررسیها
هنوز بررسیای ثبت نشده است.