توضیحات
ABSTRACT
Size-based scheduling with aging has, for long,been recognized as an effective approach to guarantee fairness
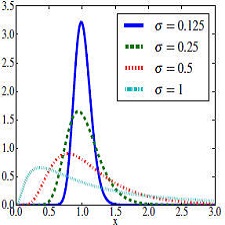
and near-optimal system response times. We present HFSP,a scheduler introducing this technique to a real, multi-server,complex and widely used system such as Hadoop.Size-based scheduling requires a priori job size information,which is not available in Hadoop: HFSP builds such knowledge by estimating it on-line during job execution.Our experiments, which are based on realistic workloads generated via a standard benchmarking suite, pinpoint at a significant decrease in system response times with respect to the widely used Hadoop Fair scheduler, and show that HFSP is largely tolerant to job size estimation errors
INTRODUCTION
The advent of large-scale data analytics, fostered by parallel processing frameworks such as MapReduce [1], has created the need to manage the resources of compute clusters that operate in a shared, multi-tenant environment. Within the same company, many users share the same cluster because this avoids redundancy (both in physical deployments and in data storage) and may represent enormous cost savings. Initially designed for few and very large batch processing jobs, data-intensive scalable computing frameworks such as MapReduce are nowadays used by many companies for production, recurrent and even experimental data analysis jobs. This heterogeneity is substantiated by recent studies
Publisher:IEEE
Year:2013
File Information :English Language/9 Page/Size:244 K
Download:click
ناشر:IEEE
سال:2013
اطلاعات فایل:زبان انگلیسی/9 صفحه/حجم:244 K
لینک دانلود:روی همین لینک کلیک کنید






نقد و بررسیها
هنوز بررسیای ثبت نشده است.