توضیحات
ABSTRACT
Data is being produced in large amounts and in rapid pace which is diverse in quality, hence, the term big data used. Now, big data has started to influence modern day life in almost every sphere, be it business, education or healthcare. Data being a part and parcel of everyday life, privacy has become a topic requiring emphasis. Privacy can be defined as the capacity of a person or group to seclude themselves or information about themselves, and thereby express them selectively. Privacy in big data can be achieved through various means but here the focus is on differential privacy. Differential privacy is one such field with one of the strongest mathematical guarantee and with a large scope of future development. Along these lines, in this paper, the fundamental ideas of sensitivity and privacy budget in differential privacy, the noise mechanisms utilized as a part of differential privacy, the composition properties, the ways through which it can be achieved and the developments in this field till date has been presented. The research gap and future directions have also been mentioned as part of this paper.
INTRODUCTION
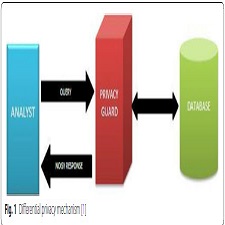
Differential privacy [1] is a technology that provides researchers and database analysts a facility to obtain the useful information from the databases that contain personal information of people without revealing the personal identities of the individuals. This is done by introducing a minimum distraction in the information provided by the database
system. The distraction introduced is large enough so that they protect the privacy and at the same time small enough so that the information provided to analyst is still useful. Earlier some techniques have been used to protect the privacy, but proved to be unsuccessful. In mid-90s when the Commonwealth of Massachusetts Group Insurance
Commission (GIC) released the anonymous health record of its clients for research to benefit the society [2]. GIC hides some information like name, street address etc. so as to protect their privacy. Latanya Sweeney (then a Ph.D. student in MIT) using the publicly available voter database and database released by GIC, successfully identified the
health record by just comparing and co-relating them. Thus hiding some information cannot assures the protection of individual identity.
چکیده
داده ها در مقادیر زیادی تولید می شوند و در سرعت های سریع و متنوعی در کیفیت هستند و از این رو، داده های بزرگ استفاده می شوند. در حال حاضر، داده های بزرگ شروع به نفوذ در زندگی روزمره در تقریبا در هر حوزه، یعنی کسب و کار، آموزش و پرورش و یا مراقبت های بهداشتی. داده ها بخشی از زندگی روزمره هستند و حفظ حریم خصوصی موضوعی است که نیاز به تأکید دارد. حریم خصوصی می تواند به عنوان ظرفیت یک فرد یا گروه تعریف شود که خود یا اطلاعات مربوط به خود را از بین می برد و به این ترتیب آنها را انتخابی بیان می کند. خصوصیات داده های بزرگ را می توان از طریق روش های مختلف به دست آورد، اما در اینجا تمرکز بر خصوصی بودن دیفرانسیل. حریم خصوصی دیفرانسیل یکی از مهمترین تضمین های ریاضی و با گستره وسیعی از توسعه های آینده است. در کنار این خطوط، در این مقاله، ایده های اساسی حساسیت و بودجه حریم خصوصی در حریم خصوصی دیفرانسیل، مکانیسم های سر و صدا به عنوان بخشی از حریم خصوصی دیفرانسیل، خواص ترکیب، راه هایی که از آن می توان به دست آورد و تحولات در این زمینه تا تاریخ ارائه شده است. شکاف تحقیق و جهت های آینده نیز به عنوان بخشی از این مقاله ذکر شده است.
مقدمه





![Formation of carcinogenic 4(5)-methylimidazole in caramel model systems[taliem.ir]](http://taliem.ir/wp-content/uploads/Formation-of-carcinogenic-45-methylimidazole-in-caramel-model-systemstaliem.ir_-150x150.jpg)
![Performance assessment of food safety management system in the[taliem.ir]](http://taliem.ir/wp-content/uploads/Performance-assessment-of-food-safety-management-system-in-thetaliem.ir_-150x150.jpg)
نقد و بررسیها
هنوز بررسیای ثبت نشده است.