توضیحات
ABSTRACT
Handling huge amount of data scalably is a matter of concern for a long time. Same is true for semantic web data. Current semantic web frameworks lack this ability. In this paper,we describe a framework thatwe built usingHadoop1 to store and retrieve large number of RDF2 triples.We describe our schema to store RDF data in Hadoop Distribute File System. We also present our algorithms to answer a SPARQL3 query. We make use of Hadoop’s MapReduce framework to actually answer the queries. Our results reveal that we can store huge amount of semantic web data in Hadoop clusters built mostly by cheap commodity class hardware and still can answer queries fast enough. We conclude that ours is a scalable framework, able to handle large amount of RDF data efficiently
INTRODUCTION
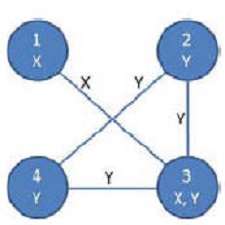
Scalibility is a major issue in IT world. Basically what it means is that a system can handle addition of large number of users, data, tasks etc. without affecting its performance significantly. Designing a scalable system is not a trivial task. This also applies to systems handling large data sets. Semantic web data repositories are no exception to that. Storing huge number of RDF triples and the ability to efficiently query them is a challenging problem which is yet to be solved. Trillions of triples requiring peta bytes of disk space is not a distant possibility any more. Researchers are already working on billions of triples[1]. Competitions are being organized to encourage researchers to build efficient repositories4
Year :2009
By:Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham
File Information :English Language/7 Page/Size:111 K
Download:click
سال :2009
کاری از : Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham
اطلاعات فایل:زبان انگلیسی/7 صفحه /حجم :111 K
لینک دانلود :روی همین لینک کلیک کنید





نقد و بررسیها
هنوز بررسیای ثبت نشده است.