توضیحات
ABSTRACT
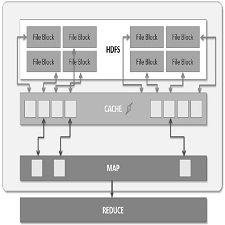
While advanced analysis of large dataset is in high demand, data sizes have surpassed capabilities of conventional software and hardware. Hadoop framework distributes large datasets over multiple commodity servers and performs parallel computations. We discuss the I/O bottlenecks of Hadoop framework and propose methods for enhancing I/O performance. A proven approach is to cache data to maximize memory-locality of all map tasks. We introduce an approach to optimize I/O, the in-node combining design which extends the traditional combiner to a node level. The in-node combiner reduces the total number of intermediate results and curtail network traffic between mappers and reducers.
INTRODUCTION
Hadoop is an open source framework that provides a reliable storing of large data collections over multiple commodity servers and parallel processing of data analysis. Since its emergence, it has firmly maintained its position as de facto standard for analyzing large datasets. Without in-depth understandings of complex concepts of a distributed system, developers can take advantages of Hadoop APIs for an efficient management and processing of the big data.
Hadoop MapReduce [1] is a software framework built on top of Hadoop used for processing large data collections in parallel on Hadoop clusters. The underlying algorithm of MapReduce is based on a common map and reduce programming model widely used in functional programming. It is particularly suitable for parallel processing as each map or reduce task operates independent of one another. MapReduce jobs are mostly I/O-bound as 70% of a single job is found to be I/O-intensive tasks
Year:2015
By:Woo-Hyun Lee, Hee-Gook Jun, and Hyoung-Joo Kim
File Information :English Language/17 Page/Size:433 K
Download:click
سال:2015
کاری از:Woo-Hyun Lee, Hee-Gook Jun, and Hyoung-Joo Kim
اطلاعات فایل:زبان انگلیسی/17 صفحه/حجم:433 K
لینک دانلود:روی همین لینک کلیک کنید




نقد و بررسیها
هنوز بررسیای ثبت نشده است.