توضیحات
ABSTRACT
We present a data-driven approach for diagnosing performance issues in heterogeneous Hadoop clusters. Hadoop is a popular and extremely successful framework for horizontally scalable distributed computing over large data sets based on the MapReduce framework. In its current implementation, Hadoop assumes a homogeneous cluster of compute nodes. This assumption manifests in Hadoop’s scheduling algorithms, but is also crucial to existing approaches for diagnosing performance issues, which rely on the peer similarity between nodes. It is desirable to enable efficient use of Hadoop on heterogeneous clusters as well as on virtual/cloud infrastructure, both of
which violate the peer-similarity assumption. To this end, we have implemented and here present preliminary results of an approach for automatically diagnosing the health of nodes in the cluster, as well as the resource requirements of incoming MapReduce jobs. We show that the approach can be used to identify abnormally performing cluster nodes and to diagnose the kind of fault occurring on the node in terms of the system resource affected by the fault (e.g., CPU contention, disk I/O contention). We also describe our future plans for using this approach to increase the efficiency of Hadoop on heterogeneous and virtual clusters with or without faults,
INTRODUCTION
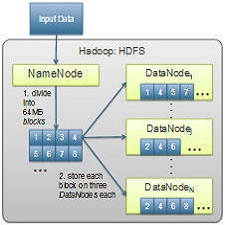
Hadoop1 is a popular and extremely successful framework for horizontally scalable distributed processing of large data sets. It is an open-source implementation of the Google filesystem (Ghemawat et al., 2003), called HDFS in Hadoop, and Google’s MapReduce framework (Dean and Ghemawat, 2008). HDFS is able to store tremendously large files across several machines and using MapReduce, such files can be processed in a distributed fashion, moving the computation to the data, rather than the other way round
Year : 2012
Publisher : International Workshop on Principles of Diagnosis
By : Shekhar Gupta, Christian Fritz, Johan de Kleer, and Cees Witteveen
File Information : English Language /8 Page / Size :487 K
Download :click
سال : 2012
ناشر :International Workshop on Principles of Diagnosis
کاری از :Shekhar Gupta, Christian Fritz, Johan de Kleer, and Cees Witteveen
اطلاعات فایل : زبان انگلیسی / 8 صفحه /حجم : 487 K
لینک دانلود : روی همین لینک کلیک کنید



نقد و بررسیها
هنوز بررسیای ثبت نشده است.