توضیحات
ABSTRACT
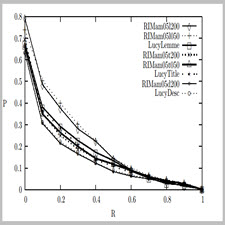
Based on the idea that the closer the query terms are in a document, the more relevant this document is, we experiment an IR method based on a fuzzy proximity degree of the query term occurences in a document to compute its relevance to the query. Our model is able to deal with Boolean queries, but contrary to the traditional extensions of the basic Boolean IR model, it does not explicitly use a proximity operator. The fuzzy term proximity is controlled with an influence function. Given a query term and a document, the influence function associates to each position in the text a value dependant on the distance of the nearest occurence of this query term. To model proximity, this function is decreasing with distance. Different forms of function can be used: triangular, gaussian etc. For practical reasons only functions with finite support were used. The support of the function is limited by a constant called k. The fuzzy term proximity functions are associated to every leaves of the query tree. Then fuzzy proximities are computed for every nodes with a post-order tree traversal. Given the fuzzy proximities of the sons of a node, its fuzzy proximity is computed, like in the fuzzy IR models, with a mimimum (resp. maximum) combination for conjunctives (resp. disjunctives) nodes. Finally, a fuzzy query proximity value is obtained for each position in this document at the root of the query tree. The score of this document is the integration of the function obtained at the tree root. For the experiments, we modified Lucy (version 0.5.2) to implement our IR model. Three query sets are used for our eight runs. One set is manually built with the title words and some description words. Each of these words is OR’ed with its derivatives like plurals for instance. Then the OR nodes obtained are AND’ed at the tree root. The two automatic query sets are built with an AND of automatically extracted terms from either the title field or the description field. These three query sets are submitted to our system with two values of k: 50 and 200. As our method is aimed at high precision, it sometimes give less than one thousand answers. In such cases, the documents retrieved by the BM-25 method implemented in Lucy was concatenated after our result list.
INTRODUCTION
In the information retrieval domain, the systems are based on three basic models: The Boolean model, the vector model and the probabilistic model. These models were derived within many variations (extended Boolean models, models based on fuzzy sets theory, generalized vector space model,…) [1]. Though, all of them are based on weak representations of documents: either sets of terms or bags of terms. In the first case, what the information retrieval system knows about a document is if it contains or not a given term. In the second case, the system knows the number of occurences – the term frequency, tf – of a given term in each document. So whatever is the order of the terms in the documents, they share the same index representation if they use the same terms. The worthy of note exceptions are most of the Boolean model implementations which propose a near operator [10]. This operator is a kind of and but with the constraint that the different terms are within a window of size n, where n is an integral value.
Year: 2016
Publisher : ENSM-SE
By : Annabelle Mercier and Michel Beigbeder
File Information: English Language/ 10 Page / size: 157 KB
Download: click
سال : 2016
ناشر : ENSM-SE
کاری از : Annabelle Mercier and Michel Beigbeder
اطلاعات فایل : زبان انگلیسی / 10 صفحه / حجم : KB 157
لینک دانلود : روی همین لینک کلیک کنید






نقد و بررسیها
هنوز بررسیای ثبت نشده است.