توضیحات
ABSTRACT
As a widely-used parallel computing framework for big data processing today, the Hadoop MapReduce framework puts more emphasis on high-throughput of data than on low-latency of job execution. However, today more and more big data applications developed with MapReduce require quick response time. As a result, improving the performance of MapReduce jobs, especially for short jobs, is of great significance in practice and has attracted more and more attentions from both academia and industry. A lot of efforts have been made to improve the performance of Hadoop from job scheduling or job parameter optimization level. In this paper, we explore an approach to improve the performance of the Hadoop MapReduce framework by optimizing the job and task execution mechanism. First of all, by analyzing the job and task execution mechanism in MapReduce framework we reveal two critical limitations to job execution performance. Then we propose two major optimizations to the MapReduce job and task execution mechanisms: first, we optimize the setup and cleanup tasks of a MapReduce job to reduce
the time cost during the initialization and termination stages of the job; second, instead of adopting the loose heartbeat-based communication mechanism to transmit all messages between the JobTracker and TaskTrackers, we introduce an instant messaging communication mechanism for accelerating performance-sensitive task scheduling and execution. Finally, we implement SHadoop, an optimized and
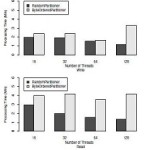
fully compatible version of Hadoop that aims at shortening the execution time cost of MapReduce jobs, especially for short jobs. Experimental results show that compared to the standard Hadoop, SHadoop can achieve stable performance improvement by around 25% on average for comprehensive benchmarks without losing scalability and speedup. Our optimization work has passed a production-level test in Intel and has been integrated into the Intel Distributed Hadoop (IDH). To the best of our knowledge, this work is the first effort that explores on optimizing the execution mechanism inside map/reduce tasks of a job. The advantage is that it can complement job scheduling optimizations to further improve the job execution performance
INTRODUCTION
The MapReduce parallel computing framework [7], proposed by Google in 2004, has become an effective and attractive solution for big data processing problems. Through simple programming interfaces with two functions, map and reduce, MapReduce significantly simplifies the design and implementation of many data-intensive applications in the real world
Publisher:ELSEVIER
Year:2013
By:Rong Gu, Xiaoliang Yang, Jinshuang Yan, Yuanhao Sun, Bing Wang,Chunfeng Yuan, Yihua Huang
File Information:English Language /14 Page / Size:1.9 M
Download:click
ناشر:ELSEVIER
سال :2013
کاری از:Rong Gu, Xiaoliang Yang, Jinshuang Yan, Yuanhao Sun, Bing Wang,Chunfeng Yuan, Yihua Huang
اطلاعات فایل:زبان انگلیسی /14 صفحه/ حجم :1.9 M
لینک دانلود :روی همین لینک کلیک کنید




نقد و بررسیها
هنوز بررسیای ثبت نشده است.