
توضیحات
ABSTRACT
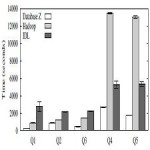
In this paper, we introduce a theoretical basis for a Hadoop-based neural network for parallel and distributed feature selection in Big Data sets. It is underpinned by an associative memory (binary) neural network which is highly amenable to parallel and distributed processing and fits with the Hadoop paradigm. There are many feature selectors described in the literature which all have various strengths and weaknesses. We present the implementation details of five feature selection algorithms constructed using our artificial neural network framework embedded in Hadoop YARN. Hadoop allows parallel and distributed processing. Each feature selector can be divided into subtasks and the subtasks can then be processed in parallel. Multiple feature selectors can also be processed simultaneously (in parallel) allowing multiple feature selectors to be compared. We identify commonalities among the five features selectors. All can be processed in the framework using a single representation and the overall processing can also be greatly reduced by only processing the common aspects of the feature selectors once and
propagating these aspects across all five feature selectors as necessary. This allows the best feature selector and the actual features to select to be identified for large and high dimensional data sets through exploiting the efficiency and flexibility of embedding the binary associative-memory neural network in Hadoop
INTRODUCTION
The meaning of ‘‘big’’ with respect to data is specific to each application domain and dependent on the computational resources available. Here we define ‘‘Big Data’’ as large, dynamic collections of data that cannot be processed using traditional techniques, a definition adapted from (Franks, 2012; Zikopoulos
& Eaton, 2011). Today, data is generated continually by an increasing range of processes and in ever increasing quantities driven by Big Data mechanisms such as cloud computing and on-line services. Business and scientific data from many fields, such as finance, astronomy, bioinformatics and physics, are often measured in terabytes (1012 bytes). Big Data is characterised by its complexity, variety, speed of processing and volume (Laney, 2001). It is
increasingly clear that exploiting the power of these data is essential for information mining. These data often contain too much noise (Liu, Motoda, Setiono, & Zhao, 2010) for accurate classification (Dash & Liu, 1997; Han & Kamber, 2006),
Publisher:ELSEVIER
Year:2016
By :Victoria J. Hodge, Simon O’Keefe , Jim Austin
File Information : English Language/12 Page/Size :782 K
Download :click
ناشر :ELSEVIER
سال :2016
کاری از :Victoria J. Hodge, Simon O’Keefe , Jim Austin
اطلاعات فایل :زبان انگلیسی /12 صفحه /حجم :782 K
لینک دانلود :روی همین لینک کلیک کنید

نقد و بررسیها
هنوز بررسیای ثبت نشده است.