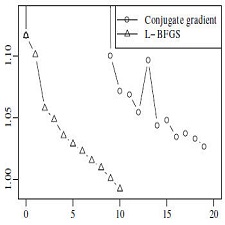
توضیحات
ABSTRACT
Many modern enterprises are collecting data at the most detailed level possible, creating data repositories ranging from terabytes to petabytes in size. The ability to apply sophisticated statistical analysis methods to this data is becoming essential for marketplace competitiveness. This need to perform deep analysis over huge data repositories poses a significant challenge to existing statistical software and data management systems. On the one hand, statistical software provides rich functionality for data analysis and modeling, but can handle only limited amounts of data; e.g., popular packages like R and SPSS operate entirely in main memory. On the other hand, data management systems—such as MapReduce-based systems—can scale to petabytes of data, but provide insufficient
analytical functionality. We report our experiences in building Ricardo, a scalable platform for deep analytics. Ricardo is part of the eXtreme Analytics Platform (XAP) project at the IBM Almaden Research Center, and rests on a decomposition of data-analysis algorithms into parts executed by the R statistical analysis system and parts handled by the Hadoop data management system. This decomposition attempts to minimize the transfer of data across system boundaries. Ricardo contrasts with previous approaches, which try to get along with only one type of system, and allows analysts to work on huge datasets from within a popular, well supported, and powerful analysis environment. Because our approach avoids the need to re-implement either statistical or data-management functionality , it can be used to solve complex problems right now
INTRODUCTION
Many of today’s enterprises collect data at the most detailed level possible, thereby creating data repositories ranging from terabytes to petabytes in size. The knowledge buried in these enormous datasets is invaluable for understanding and boosting business performance. The ability to apply sophisticated statistical analysis methods to this data can provide a significant competitive edge in the marketplace. For example, internet companies such as Amazon or Netflix provide personalized recommendations of products to their customers, incorporating information about individual preferences. These recommendations increase customer satisfaction and thus play an important role in building, maintaining, and expanding a loyal customer base. Similarly, applications like internet search and ranking, fraud detection, risk assessment, microtargeting, and ad placement gain significantly from fine-grained analytics at the level of individual entities. This paper is about the development of industrial-strength systems that support advanced statistical analysis over huge amounts of data
Year : 2010
By : Sudipto Das,Yannis Sismanis,Kevin S. Beyer,Rainer Gemulla,Peter J. Haas,John McPherson
File Information : English Language /12 Page / Size : 532 K
Download : click
سال : 2010
کاری از : Sudipto Das,Yannis Sismanis,Kevin S. Beyer,Rainer Gemulla,Peter J. Haas,John McPherson
اطلاعات فایل : زبان انگلیسی / 12 صفحه /حجم : 532 K
لینک دانلود : روی همین لینک کلیک کنید




نقد و بررسیها
هنوز بررسیای ثبت نشده است.