
توضیحات
ABSTRACT
Big data analytics (BDA) applications are a new category of software applications that process large amounts of data
using scalable parallel processing infrastructure to obtain hidden value. Hadoop is the most mature open-source big
data analytics framework, which implements the MapReduce programming model to process big data with
MapReduce jobs. Big data analytics jobs are often continuous and not mutually separated. The existing work mainly
focuses on executing jobs in sequence, which are often inefficient and consume high energy. In this paper, we
propose a genetic algorithm-based job scheduling model for big data analytics applications to improve the efficiency
of big data analytics. To implement the job scheduling model, we leverage an estimation module to predict the
performance of clusters when executing analytics jobs. We have evaluated the proposed job scheduling model in
terms of feasibility and accuracy
INTRODUCTION
Big data analytics (BDA) applications are a new category of software applications that process large amounts
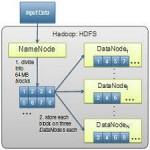
of data using scalable parallel processing infrastructure to obtain hidden value. Hadoop [1] is the most mature
open-source big data analytics framework, which implements the MapReduce programming model [2] proposed
by Google in 2004 to process big data. Scalability is the most important feature of Hadoop, mainly because it can
easily add compute nodes in the original cluster to analyze big data
The performance of big data analytics application is related to the characteristics of jobs and the configuration
of clusters, which have a direct impact on performance of big data analytics applications. When there are multiple
jobs that need to be executed with diverse cluster configurations, the solution space of job scheduling is huge
and manual job scheduling is inefficient and can hardly achieve the best performance
Year : 2016
Publisher : Springer
By : Qinghua Lu, Shanshan Li, Weishan Zhang and Lei Zhang
File Information : English Langlish / 9 Page/Size : 546 K
Download : click
سال : 2016
ناشر : Springer
کاری از : Qinghua Lu, Shanshan Li, Weishan Zhang and Lei Zhang
اطلاعات فایل :زبان انگلیسی /9 صفحه /حجم : 546 K
لینک دانلود :روی همین لینک کلیک کنید




نقد و بررسیها
هنوز بررسیای ثبت نشده است.