توضیحات
ABSTRACT
Hadoop is a Java-based programming framework that supports the storing and processing of large data sets in a distributed computing environment and it is very much appropriate for high volume of data. it’s using HDFS for data storing and using MapReduce to processing that data. MapReduce is a popular programming model to support data-intensive applications using shared-nothing clusters. the main objective of MapReduce programming model is to parallelize the job execution across multiple nodes for execution. nowadays, all focus of the researchers and companies toward to Hadoop. due this, many scheduling algorithms have been proposed in the past decades. there are three important scheduling issues in MapReduce such as locality, synchronization and fairness. The most common objective of scheduling algorithms is to minimize the completion time of a parallel application and also achieve to these issues. in this paper, we describe the overview of Hadoop MapReduce and their scheduling issues and problems. then, we have studies of most popular scheduling algorithms in this field. finally, highlighting the
implementation Idea, advantages and disadvantage of these algorithms.
INTRODUCTION
Hadoop is much more than a highly available, massive data storage engine. One of the main advantages of using Hadoop is that you can combine data storage and processing . it can provide much needed robustness and scalability option to a distributed system as Hadoop provides inexpensive and reliable storage. Hadoop using
HDFS for data storing and using MapReduce to processing that data.HDFS is Hadoop’s implementation of a distributed filesystem. It is designed to hold a large amount of data, and provide access to this data to many clients
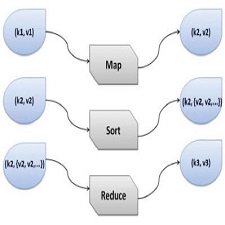
distributed across a network .MapReduce is an excellent model for distributed computing, introduced by Google in 2004. Each MapReduce job is composed of a certain number of map and reduce tasks.The MapReduce model for serving multiple jobs consists of a processor sharing queue for the Map Tasks and a multi-server queue for the
Reduce Tasks
Year : 2014
Publisher : International Journal of Computer Networks and Communications Security
By : Seyed Reza Pakize
File Information : English Language /10 Page /Size : 289 KB
Download : click
سال : 2014
ناشر : International Journal of Computer Networks and Communications Security
کاری از : Seyed Reza Pakize
اطلاعات فایل : زبان انگلیسی /10 صفحه / حجم : KB 289
لینک دانلود : روی همین لینک کلیک کنید


نقد و بررسیها
هنوز بررسیای ثبت نشده است.